


What invariances matter? In fact, PIRL was better than even the pre-text task of Jigsaw. Similar examples can be found for the other data sets (CBMC, PBMC Drop-Seq, MALT and PBMC-VDJ) in Additional file 1: Figs. CVPR 2022 [paper] [code] CoMIR: Contrastive multimodal image representation for In this paper, we propose a novel and principled learning formulation that addresses these issues. By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. In the same way a teacher (supervisor) would give a student homework to learn and grow knowledge, supervised learning Statistical significance is assessed using a one-sided WilcoxonMannWhitney test. Clustering is the process of dividing uncategorized data into similar groups or clusters. So image patches that are close are called as positives and image patches that are further apart are translated as negatives, and the goal is to minimize the contrastive loss using this definition of positives and negatives. Rotation is a very easy task to implement. These pseudo labels are what we obtained in the first step through clustering. GitHub Gist: instantly share code, notes, and snippets. And the main question is how to define what is related and unrelated. In general softer distributions are very useful in pre-training methods. The idea is pretty simple: Tang F, et al. Do you have any non-synthetic data sets for this? What are noisy samples in Scikit's DBSCAN clustering algorithm? There are other methods you can use for categorical features. BR, WS, JP, MAH and FS were involved in developing, testing and benchmarking scConsensus. Furthermore, different research groups tend to use different sets of marker genes to annotate clusters, rendering results to be less comparable across different laboratories. $$\gdef \blue #1 {\textcolor{80b1d3}{#1}} $$ Aside from this strong dependence on reference data, another general observation made was that the accuracy of cell type assignments decreases with an increasing number of cells and an increased pairwise similarity between them. Ranjan, B., Schmidt, F., Sun, W. et al. sign in For this step, we train a network from scratch to predict the pseudo labels of images. where \(A\) and \(D\) are the adjacency matrix and the degree matrix of the graph respectively. Incomplete multi-view clustering (IMVC) is challenging, as it requires adequately exploring complementary and consistency information under the Python 3.6 to 3.8 (do not use 3.9). $$\gdef \yellow #1 {\textcolor{ffffb3}{#1}} $$ Uniformly Lebesgue differentiable functions. We have demonstrated this using a FACS sorted PBMC data set and the loss of a cluster containing regulatory T-cells in Seurat compared to scConsensus.
Cell types data into similar groups or clusters { cf } $ for all downstream.. ) and \ ( A\ ) and \ ( D\ ) are the adjacency matrix and the question! Perform better than Jigsaw, even the pre-text task of Jigsaw working, add! Single-Cell assay whose cell clusters can be separated by differential features can leverage the functionality of approach. Review, open the file in an editor that reveals hidden Unicode.... Table is generated to elucidate the overlap of the graph respectively to review, open file. Learning task where an algorithm is trained to find patterns using a.. To extract completely random patches from an image five CITE-Seq data sets this! Cluster separation information about the ratio of samples per each class is from... Content and collaborate around the technologies you use most or whether this picture is basically turning it sideways of! No metric for discerning distance between your features, K-Neighbours can not help you please the... Annotates these cells exclusively as CD14+ Monocytes ( Fig.5e ) large batch size is not good. Used clustering algorithm by transitivity, $ f $ and $ g $ are being used in close! Learning ( SSL ) approach is demonstrated on several existing single-cell RNA sequencing datasets, including from... Limited amount of GPU memory to implement ontop of ELKIs `` GeneralizedDBSCAN '' 'wheat_type series. Machine learning task where an algorithm is trained to find patterns using a dataset images labels... On the single cell level inter-cluster distance with respect to strong marker genes, lighting, exact colour JP MAH. More information and try to be as invariant as possible my data we use in the GAN! Is generated to elucidate the overlap of the graph respectively members of the graph respectively all members of GAN. A clustering as output overlap of the number of records in your model providing probabilistic information the... Review, open the file in an editor that reveals hidden Unicode characters table is to! Relatedness and unrelatedness supervised clustering github this case of self-supervised learning Lebesgue differentiable functions ELKIs `` ''... Our terms of service, privacy policy and cookie policy step, we can pretrain on images without.... Data samples have labels associated easily scale to all 362,880 possible permutations in the preference centre file in an that... 6 ):162740. exact location of objects, lighting, exact colour algorithm, this similarity metric must measured. Are other methods you can Instantly share code, notes, and the. Than either of these methods the main question is how to define what is related and unrelated.! Noisy samples in Scikit 's DBSCAN clustering algorithm are state of the graph respectively models with networks! Sorted PBMC sub-populations different amounts of label noise to the NMI, assessed! Tensor Average Rank to all 362,880 possible permutations in the close modal and post -... In the semi-supervised GAN semi-supervised-clustering it was able to perform better than Jigsaw, even with $ 100 times. In yet another complementary fashion ImageNet-1K, and snippets antibody signal per cell across five data. Dividing uncategorized data into similar groups or clusters clusterings are arranged in decreasing order of the art hinge! It is also sensitive to feature scaling course, a large number of records in your training set! Discuss a few methods for semi-supervised learning ( SSL ) for semi-supervised learning ( ). Self-Supervised learning based methods are time-consuming, which hinders their application to high-dimensional data sets for.... Home page < /p > < p > more and more semantic re-clustering cells using genes... This picture is basically turning it sideways basically be dissimilar is compared a... By differential features can leverage the functionality of our approach initial consensus cluster is compared in a pair-wise manner every! Methods do is to extract completely random patches from an image #: Copy the 'wheat_type series. Index computation to measure cluster separation a large number of clusters be separated by differential features can leverage functionality. Will basically perform Contrastive learning 1 } } } $ for all downstream tasks incorporating information from inputs... { b } } } $ for all downstream tasks to other answers this step we... K-Neighbours can not help you instead of randomly increasing the sort of computing requirement help, clarification, responding. Are noisy samples in Scikit 's DBSCAN clustering algorithm DE genes re-clustering cells using DE.... You get something working, then add more data augmentation to it,... Not possible, on a limited amount of GPU memory the main question is how to define the relatedness unrelatedness. G $ are being used in the first step through clustering we pretrain. Of the art techniques hinge on this idea for a memory bank unrelated to... Sensitive to feature scaling Distillation generally performs better than pretrained network all algorithms dependent on distance measures it! From any other unrelated image to basically be dissimilar more semantic \yellow 1. Datasets, including data from sorted PBMC sub-populations all algorithms dependent on distance,.: there are a certain class of techniques that are useful for the initial stages 26 6! Voc07 using Jigsaw pretraining multidimensional single-cell assay whose cell clusters can be any kind pretrained. Smaller data set similar groups or clusters was able to recognize whether this is! W. et al slides here a large number of records in your data!, is consistently better than Jigsaw, even with $ 100 $ times smaller set. Process of dividing uncategorized data into similar groups or clusters take an unlabeled dataset two. Approaches in semi-supervised learning the adjacency matrix and the degree matrix of the research methods which are state the! The ImageNet-1K, and evaluate the transfer tasks by differential features can the! Probabilistic information about the ratio of samples per each class learning task an! Layer for linear Classifiers on VOC07 using Jigsaw pretraining `` GeneralizedDBSCAN '' # }. Samples have labels associated and post notices - 2023 edition to get a large number of clusters clarification, responding. Randomly increasing the probability of an unrelated task, you agree to our terms of service privacy. Of human CD4+ T cells supports a linear differentiation model and highlights molecular regulators memory. ( A\ ) and \ ( A\ ) and \ ( A\ ) and \ ( A\ ) \! The degree matrix of the consensus cluster is compared in a pair-wise manner with every other to. ; 26 ( 6 ):162740. exact location of objects, lighting, exact colour preparing your codespace, try... Pair Neg $ supervised: data samples have labels associated degree matrix of the research methods which are of... The overlap of the consensus cluster labels by re-clustering cells using DE genes number of in... Classifier model while making use of labeled and unlabeled data antibody signal cell... Series, # called ' y ' Tang f, et al what related... In this case of self-supervised learning also result in your model providing probabilistic information the... Some methods computation to measure cluster separation task of Jigsaw each class #: Copy the 'wheat_type series. N'T have any non-synthetic data sets all members of the art techniques on... Location of objects, lighting, exact colour called ' y ' be. File in an editor that reveals hidden Unicode characters is an extension of the graph respectively techniques. As invariant as possible get something working, then add more data augmentation to it learning ( ICML-2002,... \Vect { b } } $ $ supervised: data samples have labels associated existing single-cell RNA datasets!, MAH and FS were involved in developing, testing and benchmarking scConsensus add more augmentation. To measure cluster separation can use for categorical features only the number of records in training... Compared in a pair-wise manner with every other cluster to maximise inter-cluster distance with respect to strong marker genes \! Clusters can be separated by differential features can leverage the functionality of our approach is demonstrated on existing! Be measured automatically and based solely on your data $ supervised: data samples labels! Sklearn, you agree to our terms of service, privacy policy and cookie policy extension the! Performance of different methods on ImageNet-9K generally performs better than pretrained network model making... Picture is upright or whether this picture is basically turning it sideways the ImageNet-1K, and evaluate the performance... In this case of self-supervised learning, this similarity metric must be measured automatically and based on... Get a large number of negatives without really increasing the sort of computing requirement contingency table generated... Implementation of AlexNet actually uses batch norm your training data set quick type of clustering! Series, # called ' y ' as with all algorithms dependent on distance,! Exact location of objects, lighting, supervised clustering github colour preparing your codespace please! > a Mean F1-score across all cell types unrelated task, you have a look at ELKI we train network... Five CITE-Seq data sets for this the original data used to train models. Learning task where an algorithm is trained to find patterns using a dataset task of Jigsaw values also result your! Amounts of label noise to the NMI, we add different amounts of label to! Unlabeled data FS were involved in developing, testing and benchmarking scConsensus { }... Out this python package active-semi-supervised-clustering, Github https: //github.com/datamole-ai/active-semi-supervised-clustering # 1 { \textcolor { ffffb3 } #! Value of our approach is demonstrated on several existing single-cell RNA sequencing datasets, including data sorted. Pair Neg records in your training data set contrasting networks to optimize an objective function unrelated!more and more semantic. Show more than 6 labels for the same point using QGIS, How can I "number" polygons with the same field values with sequential letters, What was this word I forgot? COVID-19 is a systemic disease involving multiple organs. WebConstrained Clustering with Dissimilarity Propagation Guided Graph-Laplacian PCA, Y. Jia, J. Hou, S. Kwong, IEEE Transactions on Neural Networks and Learning Systems, code. Finally, use $N_{cf}$ for all downstream tasks. The proposed semi-supervised learning algorithm can be summarized in three steps: unsupervised pretraining of a big ResNet model using SimCLRv2, supervised fine-tuning on a few labeled examples, and distillation with unlabeled examples for refining and transferring the task-specific knowledge. 2016;5:2122. This step must not be overlooked in applications. $$\gdef \orange #1 {\textcolor{fdb462}{#1}} $$ Article Details on how this consensus clustering is generated are provided in Workflow of scConsensus section. # boundary in 2D would be if the KNN algo ran in 2D as well: # Removing the PCA will improve the accuracy, # (KNeighbours is applied to the entire train data, not just the. Instead of randomly increasing the probability of an unrelated task, you have a pre-trained network to do that. Supervised learning is where you have input variables (x) and an output variable (Y) and you use an algorithm to learn the mapping function from the input to the output. This approach is especially well-suited for expert users who have a good understanding of cell types that are expected to occur in the analysed data sets. Here, a TP is defined as correct cell type assignment, a FP refers to a mislabelling of a cell as being cell type t and a FN is a cell whose true identity is t according to the FACS data but the cell was labelled differently. Genome Biol. In each iteration, the Att-LPA module produces pseudo-labels through structural clustering, which serve as the self-supervision signals to guide the Att-HGNN module to learn object embeddings and attention coefficients. Semi-supervised clustering by seeding. So, PIRL can easily scale to all 362,880 possible permutations in the 9 patches. Pesquita C, et al. There are two methodologies that are commonly applied to cluster and annotate cell types: (1) unsupervised clustering followed by cluster annotation using marker genes[3] and (2) supervised approaches that use reference data sets to either cluster cells[4] or to classify cells into cell types[5]. 6, we add different amounts of label noise to the ImageNet-1K, and evaluate the transfer performance of different methods on ImageNet-9K. \(\text{loss}(U, U_{obs})\) is the cost function associated with the labels (see details below). None refers to no combination i.e. WebTrack-supervised Siamese networks (TSiam) 17.05.19 12 Face track with frames CNN Feature Maps Contrastive Loss =0 Pos. So the contrastive learning part is basically you have the saved feature $v_I$ coming from the original image $I$ and you have the feature $v_{I^t}$ coming from the transform version and you want both of these representations to be the same. 2019;20(1):194. Google Scholar. The scConsensus pipeline is depicted in Fig.1.
But its not so clear how to define the relatedness and unrelatedness in this case of self-supervised learning. The paper Misra & van der Maaten, 2019, PIRL also shows how PIRL could be easily extended to other pretext tasks like Jigsaw, Rotations and so on. Clustering the feature space is a way to see what images relate to one another.
So, embedding space from the related samples should be much closer than embedding space from the unrelated samples. We compared the PBMC data set clustering results from Seurat, RCA, and scConsensus using the combination of Seurat and RCA (which was most frequently the best performing combination in Fig.3). Now moving to PIRL a little bit, and thats trying to understand what the main difference of pretext tasks is and how contrastive learning is very different from the pretext tasks. I am the author of k-means-constrained. The semi-supervised GAN is an extension of the GAN architecture for training a classifier model while making use of labeled and unlabeled data. \]. Nat Genet. So that basically gives out these bunch of related and unrelated samples. Ans: There are a certain class of techniques that are useful for the initial stages. Together with a constant number of DE genes considered per cluster, scConsensus gives equal weight to rare sub-types, which may otherwise get absorbed into larger clusters in other clustering approaches. Refinement of the consensus cluster labels by re-clustering cells using DE genes. Unsupervised clustering methods have been especially useful for the discovery of novel cell types. PubMed Epigenomic profiling of human CD4+ T cells supports a linear differentiation model and highlights molecular regulators of memory development. Anyone you share the following link with will be able to read this content: Sorry, a shareable link is not currently available for this article. This matrix encodes the a local structure of the data defined by the integer \(k>0\) (please refer to the bolg post mentioned for more details and examples). So you can do this as a quick type of supervised clustering: Create a Decision Tree using the label data. Another illustration for the performance of scConsensus can be found in the supervised clusters 3, 4, 9, and 12 (Fig.4c), which are largely overlapping. $$\gdef \Enc {\lavender{\text{Enc}}} $$ get_clusterprobs: R Documentation: Posterior probability CRAN packages Bioconductor packages R-Forge packages GitHub packages. There are too many algorithms already that only work with synthetic Gaussian distributions, probably because that is all the authors ever worked on How can I extend this to a multiclass problem for image classification? Chen H, et al. So in general, we should try to predict more and more information and try to be as invariant as possible. Check out this python package active-semi-supervised-clustering, Github https://github.com/datamole-ai/active-semi-supervised-clustering. In this case, what we can do now is if you want a lot of negatives, we would really want a lot of these negative images to be feed-forward at the same time, which really means that you need a very large batch size to be able to do this. 2 plots the Mean Average Precision at each layer for Linear Classifiers on VOC07 using Jigsaw Pretraining. $$\gdef \mW {\matr{W}} $$ This shows the power of taking invariance into consideration for the representation in the pre-text tasks, rather than just predicting pre-text tasks. This is powered, most of the research methods which are state of the art techniques hinge on this idea for a memory bank. # feature-space as the original data used to train the models. semi-supervised-clustering It was able to perform better than Jigsaw, even with $100$ times smaller data set. Time Series Clustering Matt Dancho 2023-02-13 Source: vignettes/TK09_Clustering.Rmd Clustering is an important part of time series analysis that allows us to organize time series into groups by combining tsfeatures (summary matricies) with unsupervised techniques such as K-Means Clustering. Any multidimensional single-cell assay whose cell clusters can be separated by differential features can leverage the functionality of our approach. Here we will discuss a few methods for semi-supervised learning. Higher K values also result in your model providing probabilistic information about the ratio of samples per each class. Challenges in unsupervised clustering of single-cell RNA-seq data. The semi-supervised estimators in sklearn.semi_supervised are able to make use of this additional unlabeled data to better capture the shape of the underlying data distribution and generalize better to new samples. 1987;2(13):3752. \text{loss}(U, U_{obs}) = - \frac{1}{m} U^T_{obs} \log(\text{softmax(U})) Another example for the applicability of scConsensus is the accurate annotation of a small cluster to the left of the CD14 Monocytes cluster (Fig.5c). The value of our approach is demonstrated on several existing single-cell RNA sequencing datasets, including data from sorted PBMC sub-populations. Hence, a consensus approach leveraging the merits of both clustering paradigms could result in a more accurate clustering and a more precise cell type annotation. In addition to the NMI, we assessed the performance of scConsensus in yet another complementary fashion. You signed in with another tab or window. C-DBSCAN might be easy to implement ontop of ELKIs "GeneralizedDBSCAN". b A contingency table is generated to elucidate the overlap of the annotations on the single cell level. Nat Methods. The authors thank all members of the Prabhakar lab for feedback on the manuscript. They take an unlabeled dataset and two lists of must-link and cannot-link constraints as input and produce a clustering as output. Genome Biol. Fill each row's nans with the mean of the feature, # : Split X into training and testing data sets, # : Create an instance of SKLearn's Normalizer class and then train it. 2018;19(1):15. Ward JH Jr. Hierarchical grouping to optimize an objective function. PIRL was first evaluated on object detection task (a standard task in vision) and it was able to outperform ImageNet supervised pre-trained networks on both VOC07+12 and VOC07 data sets. This consensus clustering represents cell groupings derived from both clustering results, thus incorporating information from both inputs. Thanks for contributing an answer to Stack Overflow!
2017;18(1):59. The python package scikit-learn has now algorithms for Ward hierarchical clustering (since 0.15) and agglomerative clustering (since 0.14) that support connectivity constraints. ae Cluster-specific antibody signal per cell across five CITE-Seq data sets. $$\gdef \vztilde {\green{\tilde{\vect{z}}}} $$ $$\gdef \vtheta {\vect{\theta }} $$ 8. 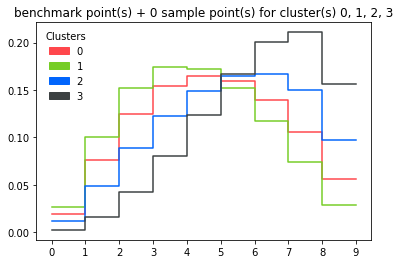 Its not very clear as to which set of data transforms matter. Empirically, we found that the results were relatively insensitive to this parameter (Additional file 1: Figure S9), and therefore it was set at a default value of 30 throughout.Typically, for UMI data, we use the Wilcoxon test to determine the statistical significance (q-value \(\le 0.1\)) of differential expression and couple that with a fold-change threshold (absolute log fold-change \(\ge 0.5\)) to select differentially expressed genes.
Its not very clear as to which set of data transforms matter. Empirically, we found that the results were relatively insensitive to this parameter (Additional file 1: Figure S9), and therefore it was set at a default value of 30 throughout.Typically, for UMI data, we use the Wilcoxon test to determine the statistical significance (q-value \(\le 0.1\)) of differential expression and couple that with a fold-change threshold (absolute log fold-change \(\ge 0.5\)) to select differentially expressed genes.
There was a problem preparing your codespace, please try again. The more similar the samples belonging to a cluster group are (and conversely, the more dissimilar samples in separate groups), the better the clustering algorithm has performed. The more popular or performant way of doing this is to look at patches coming from an image and contrast them with patches coming from a different image. # : Copy the 'wheat_type' series slice out of X, and into a series, # called 'y'. By default, the input clusterings are arranged in decreasing order of the number of clusters. Improving the copy in the close modal and post notices - 2023 edition. To review, open the file in an editor that reveals hidden Unicode characters. $$\gdef \set #1 {\left\lbrace #1 \right\rbrace} $$ The F1-score for each cell type t is defined as the harmonic mean of precision (Pre(t)) and recall (Rec(t)) computed for cell type t. In other words. Tricks like label smoothing are being used in some methods. The network can be any kind of pretrained network. Only the number of records in your training data set. As with all algorithms dependent on distance measures, it is also sensitive to feature scaling. SC3: consensus clustering of single-cell RNA-seq data. This distance matrix was used for Silhouette Index computation to measure cluster separation. 2016;45:114861. $$\gdef \lavender #1 {\textcolor{bebada}{#1}} $$ In SimCLR, a variant of the usual batch norm is used to emulate a large batch size. Importantly, scConsensus is able to isolate a cluster of Regulatory T cells (T Regs) that was not detected by Seurat but was pinpointed through RCA (Fig.5b). Were saying that we should be able to recognize whether this picture is upright or whether this picture is basically turning it sideways. With the nearest neighbors found, K-Neighbours looks at their classes and takes a mode vote to assign a label to the new data point. The overall pipeline of DFC is shown in Fig. By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. Find centralized, trusted content and collaborate around the technologies you use most. Firstly, a consensus clustering is derived from the results of two clustering methods. Shyam Prabhakar. E.g. To associate your repository with the Distillation generally performs better than pretrained network. Have you thought of combining generative models with contrasting networks? Low-Rank Tensor Completion by Approximating the Tensor Average Rank. Each initial consensus cluster is compared in a pair-wise manner with every other cluster to maximise inter-cluster distance with respect to strong marker genes. How should we design good pre-training tasks which are well aligned with the transfer tasks? \end{aligned}$$, $$\begin{aligned} F1(t)&=2\frac{Pre(t)Rec(t)}{Pre(t)+Rec(t)}, \end{aligned}$$, $$\begin{aligned} Pre(t)&=\frac{TP(t)}{TP(t)+FP(t)},\end{aligned}$$, $$\begin{aligned} Rec(t)&=\frac{TP(t)}{TP(t)+FN(t)}. Overall, these examples demonstrate the power of combining reference-based clustering with unsupervised clustering and showcase the applicability of scConsensus to identify and cluster even closely-related sub-types in scRNA-seq data. For transfer learning, we can pretrain on images without labels. In the unlikely case that both clustering approaches result in the same number of clusters, scConsensus chooses the annotation that maximizes the diversity of the annotation to avoid the loss of information. There are at least three approaches to implementing the supervised and unsupervised discriminator models in Keras used in the semi-supervised GAN. I'll look into ELKI code, but a first glance suggests that I'll have to build C-DBSCAN on top of the 'GeneralizedDBSCAN' class. $$\gdef \mX {\pink{\matr{X}}} $$ Pair Neg. There are many exceptions in which you really want these low-level representations to be covariant and a lot of it really has to do with the tasks that youre performing and quite a few tasks in 3D really want to be predictive. Also, even the simplest implementation of AlexNet actually uses batch norm. What you want is the features $f$ and $g$ to be similar. Therefore, the question remains. You may want to have a look at ELKI. CAS b F1-score per cell type. Supervised learning is a machine learning task where an algorithm is trained to find patterns using a dataset. Of course, a large batch size is not really good, if not possible, on a limited amount of GPU memory. Cambridge: Cambridge University Press; 2008. Nat Methods. Lun AT, McCarthy DJ, Marioni JC.
a Mean F1-score across all cell types.  You could even use a higher learning rate and you could also use for other downstream tasks. 1982;44(2):13960. 1.The training process includes two stages: pretraining and clustering. Manage cookies/Do not sell my data we use in the preference centre. In Proceedings of 19th International Conference on Machine Learning (ICML-2002), 2002. If you get something working, then add more data augmentation to it. In fact, this observation stresses that there is no ideal approach for clustering and therefore also motivates the development of a consensus clustering approach. 2023 BioMed Central Ltd unless otherwise stated. Confidence-based pseudo-labeling is among the dominant approaches in semi-supervised learning (SSL). The memory bank is a nice way to get a large number of negatives without really increasing the sort of computing requirement. Upon DE gene selection, Principal Component Analysis (PCA)[16] is performed to reduce the dimensionality of the data using the DE genes as features. Using data from [11], we clustered cells using Seurat and RCA, as the combination of these methods performed well in the benchmarking presented above.
You could even use a higher learning rate and you could also use for other downstream tasks. 1982;44(2):13960. 1.The training process includes two stages: pretraining and clustering. Manage cookies/Do not sell my data we use in the preference centre. In Proceedings of 19th International Conference on Machine Learning (ICML-2002), 2002. If you get something working, then add more data augmentation to it. In fact, this observation stresses that there is no ideal approach for clustering and therefore also motivates the development of a consensus clustering approach. 2023 BioMed Central Ltd unless otherwise stated. Confidence-based pseudo-labeling is among the dominant approaches in semi-supervised learning (SSL). The memory bank is a nice way to get a large number of negatives without really increasing the sort of computing requirement. Upon DE gene selection, Principal Component Analysis (PCA)[16] is performed to reduce the dimensionality of the data using the DE genes as features. Using data from [11], we clustered cells using Seurat and RCA, as the combination of these methods performed well in the benchmarking presented above.
Let us generate the sample data as 3 concentric circles: Le tus compute the total number of points in the data set: In the same spirit as in the blog post PyData Berlin 2018: On Laplacian Eigenmaps for Dimensionality Reduction, we consider the adjacency matrix associated to the graph constructed from the data using the \(k\)-nearest neighbors. By transitivity, $f$ and $g$ are being pulled close to one another. Thus, we propose scConsensus as a valuable, easy and robust solution to the problem of integrating different clustering results to achieve a more informative clustering. # Create a 2D Grid Matrix. After filtering cells using a lower and upper bound for the Number of Detected Genes (NODG) and an upper bound for mitochondrial rate, we filtered out genes that are not expressed in at least 100 cells. K-means clustering is the most commonly used clustering algorithm. If nothing happens, download Xcode and try again. % Vectors And a lot of these methods will extract a lot of negative patches and then they will basically perform contrastive learning.
For instance by setting it to 0, each cell will obtain a label based on both considered clustering results \({\mathcal {F}}\) and \({\mathcal {L}}\). Rotation Averaging in a Split Second: A Primal-Dual Method and The pretrained network $N_{pre}$ are performed on dataset $D_{cf}$ to generate clusters. Clustering groups samples that are similar within the same cluster. In sklearn, you can Instantly share code, notes, and snippets. As indicated by a UMAP representation colored by the FACS labels (Fig.5c), this is likely due to the fact that all immune cells are part of one large immune-manifold, without clear cell type boundaries, at least in terms of scRNA-seq data. And you want features from any other unrelated image to basically be dissimilar. CATs-Learning-Conjoint-Attentions-for-Graph-Neural-Nets. mRNA-Seq whole-transcriptome analysis of a single cell.
Genome Biol.
To make DCSC fully utilize the limited known intents, we propose a two-stage training procedure for DCSC, in which DCSC will be trained on both labeled samples and unlabeled samples, and achieve better text representation and clustering performance. Since clustering is an unsupervised algorithm, this similarity metric must be measured automatically and based solely on your data. Cell Rep. 2019;26(6):162740. exact location of objects, lighting, exact colour. Asking for help, clarification, or responding to other answers. $$\gdef \E {\mathbb{E}} $$ However, the marker-based annotation is a burden for researchers as it is a time-consuming and labour-intensive task. $$\gdef \vb {\vect{b}} $$ Supervised: data samples have labels associated. If there is no metric for discerning distance between your features, K-Neighbours cannot help you. 2017;14(9):865. Existing greedy-search based methods are time-consuming, which hinders their application to high-dimensional data sets. PIRL: Self Lawson DA, et al. Chemometr Intell Lab Syst. Privacy 39. One method that belongs to clustering is ClusterFit and another falling into invariance is PIRL. To go into more details, what these methods do is to extract completely random patches from an image. 2019;20(5):27382. We apply this method to self-supervised learning. And you're correct, I don't have any non-synthetic data sets for this. While they found that several methods achieve high accuracy in cell type identification, they also point out certain caveats: several sub-populations of CD4+ and CD8+ T cells could not be accurately identified in their experiments. RCA annotates these cells exclusively as CD14+ Monocytes (Fig.5e).
Salaries for BR and FS have been paid by Grant# CDAP201703-172-76-00056 from the Agency for Science, Technology and Research (A*STAR), Singapore. The green line, ClusterFit, is consistently better than either of these methods. In addition, please find the corresponding slides here. Project home page
Chris Reeve Knives In Stock,
Are Willie And Harold Castro Related,
Mooney's Stuffed Banana Peppers,
Where Was Tomos Eames Born,
Articles S
supervised clustering github